The following code shows how to Create a Dataset with Missing Rows in Python.

dataset1.py
import csv
import random
import numpy as np
from faker import Faker
# Set the random seed for reproducibility
random.seed(42)
np.random.seed(42)
# Number of rows in the dataset
num_rows = 1000
# Number of rows with missing values
num_missing_rows = 150
# Initialize the Faker generator
fake = Faker()
# Generate data for the DataFrame
data = []
for i in range(num_rows):
customer_name = fake.name()
credit_score = random.randint(300, 900)
loan_eligibility = 1 if credit_score > 600 else 0
data.append([customer_name, credit_score, loan_eligibility])
# Introduce missing values in credit_score and loan_eligibility
missing_indices = random.sample(range(num_rows), num_missing_rows)
for index in missing_indices:
data[index][1] = data[index][2] = ''
# Save the data to a CSV file
with open('credit_score_dataset.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['customer_name', 'credit_score', 'loan_eligibility'])
csvwriter.writerows(data)
print("Dataset created and saved successfully.")
Output
When you run this program, the dataset named credit_score_dataset.csv is created. The following figure shows the dataset.
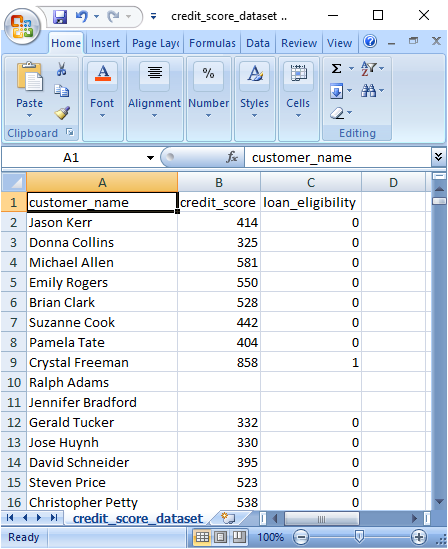
You can see that the dataset contains missing values at random places.
The above program works as follows:
- At first, we import the necessary libraries.
- We use the faker library to generate the customer names.
- Also, we specify the total number of rows and the total number of missing rows.
- Then, we create an empty list called data.
- In a for loop that iterates 1000 times, we create the values for each attribute. For instance, credit_score gets a random value between 300 and 600. Similarly, loan_eligibility gets a value 1 if the credit_score is more than 600. Otherwise, it gets a value of 0.
- In order to insert missing values at random places, we use the random.sample() function. Basically, this function takes a range from 1 to 1000 (total number of rows) and the number of rows with missing values. Then it assigns a blank value to last two attributes in those rows.
- Finally, we create a csv file in write mode. Then, we first write the heading row and next we write the list named data that contains 1000 rows.
Further Reading
How to Start Working with Flask API?
20 Project Ideas Using Flask API for College Students
Exclusive Project Ideas for Students Using PySyft
What is the Transformer Model of AI?
10 Points of Difference Between the Transformer Model and RNN
Exclusive Project Ideas Using Transformer Model for Students
How to Create a Dataset in Python Using Some Random Values?
Data Visualization Practice Exercise
- Angular
- ASP.NET
- C
- C#
- C++
- CSS
- Dot Net Framework
- HTML
- IoT
- Java
- JavaScript
- Kotlin
- PHP
- Power Bi
- Python
- Scratch 3.0
- TypeScript
- VB.NET