The following program demonstrates How to Implement Linear Regression from Scratch.

Problem Statement
Implement a linear regression with one variable algorithm from scratch using Python. Given a dataset of X and Y values, create a linear regression model that predicts Y based on X without using any machine learning libraries like sklearn.
Solution
The following code shows a simple implementation of a linear regression with one variable (univariate linear regression) from scratch in Python without using any machine learning libraries like sklearn. Also, we’ll implement the gradient descent algorithm to find the best-fitting line.
import numpy as np
# Generate sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
Y = 4 + 3 * X + np.random.rand(100, 1)
# Define the number of iterations and learning rate for gradient descent
num_iterations = 1000
learning_rate = 0.01
# Initialize the slope (theta1) and intercept (theta0)
theta0 = np.random.randn()
theta1 = np.random.randn()
# Perform gradient descent
for iteration in range(num_iterations):
# Calculate the predicted values
predicted = theta0 + theta1 * X
# Calculate the errors
errors = predicted - Y
# Calculate the gradients
gradient0 = np.sum(errors) / len(X)
gradient1 = np.sum(errors * X) / len(X)
# Update the parameters using the gradients and learning rate
theta0 = theta0 - learning_rate * gradient0
theta1 = theta1 - learning_rate * gradient1
# Print the final values of theta0 and theta1
print("Final theta0:", theta0)
print("Final theta1:", theta1)
# Predict Y for a new input
new_x = 2.5 # New input value
predicted_y = theta0 + theta1 * new_x
print("Predicted Y for X =", new_x, "is", predicted_y)
Output
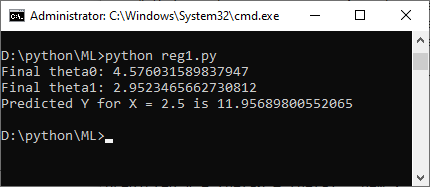
In this code:
- At first, we generate some sample data (X and Y) to work with.
- Then, we initialize the slope (theta1) and intercept (theta0) with random values.
- Further, we use gradient descent to iteratively update theta0 and theta1 to minimize the mean squared error (MSE) between the predicted values and the actual values.
- After running the gradient descent algorithm, we print the final values of theta0 and theta1, which represent the coefficients of the linear regression model.
- Finally, we make a prediction for a new input value (new_x) using the learned model.
Furthermore, you can replace the sample data with your own dataset to perform linear regression on real-world data.
Further Reading
How to Perform Dataset Preprocessing in Python?
Spring Framework Practice Problems and Their Solutions
Getting Started with Data Analysis in Python
Wake Up to Better Performance with Hibernate
Data Science in Insurance: Better Decisions, Better Outcomes
Breaking the Mold: Innovative Ways for College Students to Improve Software Development Skills
- Angular
- ASP.NET
- C
- C#
- C++
- CSS
- Dot Net Framework
- HTML
- IoT
- Java
- JavaScript
- Kotlin
- PHP
- Power Bi
- Python
- Scratch 3.0
- TypeScript
- VB.NET