The following article demonstrates How to Perform Dataset Preprocessing in Python.

Basically, dataset preprocessing is a crucial step before training a machine learning model. For this purpose, we need to handle the missing values and the categorical data. Further, we need to split the dataset into training and test datasets. The following program demonstrates how to perform descriptive statistics, handle missing data, handle categorical data, and partition a dataset into training and test datasets using the Titanic dataset as an example. In order to run this code, you’ll need to have Pandas, NumPy, Scikit-Learn, and Seaborn installed.
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.impute import SimpleImputer
# Load the Titanic dataset from Seaborn
titanic = sns.load_dataset('titanic')
# Display the first few rows of the dataset
print("First few rows of the Titanic dataset:")
print(titanic.head())
# Descriptive statistics
print("\nDescriptive statistics of the dataset:")
print(titanic.describe())
# Handling missing data
print("\nHandling missing data:")
# Check for missing values
print("Number of missing values in each column:")
print(titanic.isnull().sum())
# Fill missing values in the 'age' column with the mean age
imputer = SimpleImputer(strategy='mean')
titanic['age'] = imputer.fit_transform(titanic[['age']])
# Drop rows with missing values in the 'embarked' column
titanic.dropna(subset=['embarked'], inplace=True)
# Handling categorical data
print("\nHandling categorical data:")
# Encode categorical columns 'sex' and 'embarked' using Label Encoding
label_encoder = LabelEncoder()
titanic['sex'] = label_encoder.fit_transform(titanic['sex'])
titanic['embarked'] = label_encoder.fit_transform(titanic['embarked'])
# Display the modified dataset
print(titanic.head())
# Partition the dataset into training and test datasets
print("\nPartitioning the dataset into training and test datasets:")
X = titanic.drop('survived', axis=1) # Features
y = titanic['survived'] # Target variable
# Split the data into 80% training and 20% testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Display the shapes of the resulting datasets
print("Shape of X_train:", X_train.shape)
print("Shape of X_test:", X_test.shape)
print("Shape of y_train:", y_train.shape)
print("Shape of y_test:", y_test.shape)
Output
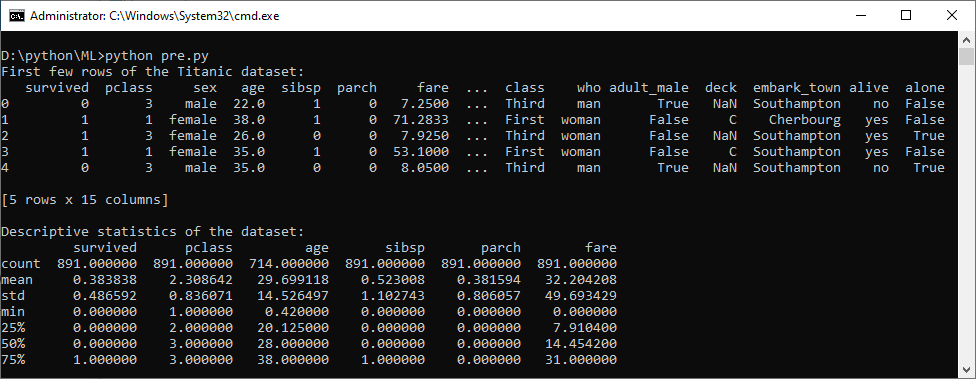
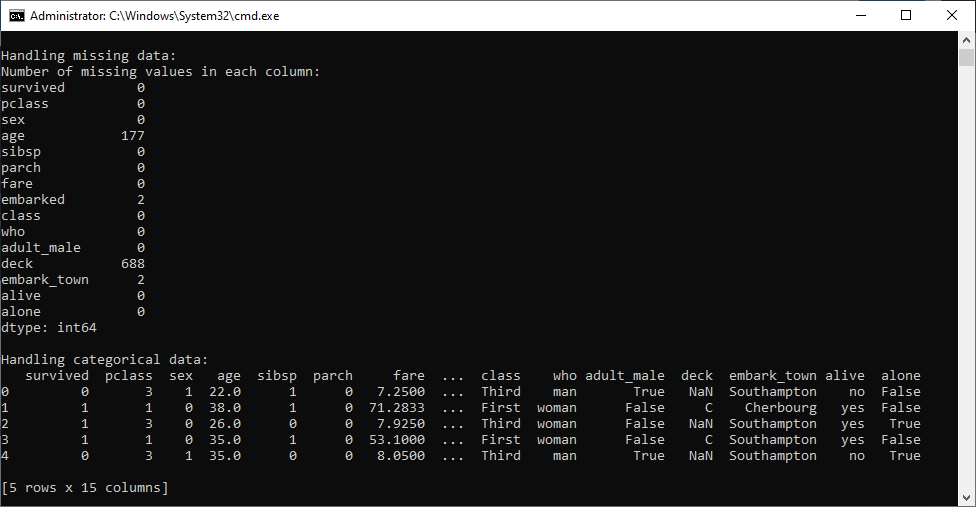
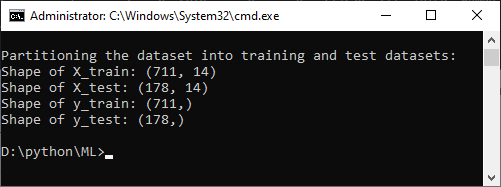
This program loads the Titanic dataset, computes descriptive statistics, handles missing data by imputing values and dropping rows, encodes categorical data, and finally, partitions the dataset into training and test datasets for machine learning tasks. In general, you can apply similar concepts to other datasets as well.
Further Reading
Spring Framework Practice Problems and Their Solutions
Why Rust? Exploring the Advantages of Rust Programming
Getting Started with Data Analysis in Python
Wake Up to Better Performance with Hibernate
Data Science in Insurance: Better Decisions, Better Outcomes
Breaking the Mold: Innovative Ways for College Students to Improve Software Development Skills
- Angular
- ASP.NET
- C
- C#
- C++
- CSS
- Dot Net Framework
- HTML
- IoT
- Java
- JavaScript
- Kotlin
- PHP
- Power Bi
- Python
- Scratch 3.0
- TypeScript
- VB.NET