In this article on Getting Started with Data Analysis in Python, we will cover common data manipulation tasks. Particularly, we will cover common tasks such as loading CSV files and extracting specific columns, filtering, sorting, and merging datasets

Getting Started with Data Analysis in Python: Loading and Displaying CSV Files
Welcome to our comprehensive guide on data manipulation and analysis using Python and the powerful pandas library. In today’s data-driven world, the ability to load, transform, and analyze data is a fundamental skill for professionals across various domains, from data scientists to business analysts. In this blog, we will explore practical solutions to common data manipulation tasks. From loading CSV files and extracting specific columns to filtering, sorting, and merging datasets, we’ll walk you through each step with clear explanations and hands-on examples. So, let’s dive in and unlock the full potential of Python and pandas for your data analysis needs!
Exercises
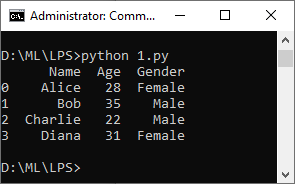
a. Load a CSV file called “data.csv” into a DataFrame and display its contents
The following exercise uses this dataset: data.csv
import pandas as pd
# Load the CSV file into a DataFrame
data = pd.read_csv("data.csv")
# Display the contents of the DataFrame
print(data)
Output
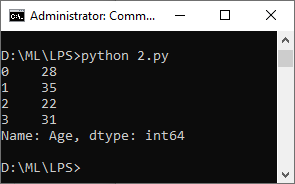
b. Extract only the “Age” column from a DataFrame with columns “Name,” “Age,” and “Gender”
import pandas as pd
# Load the CSV file into a DataFrame
data = pd.read_csv("data.csv")
age_column = data["Age"]
print(age_column)
Output
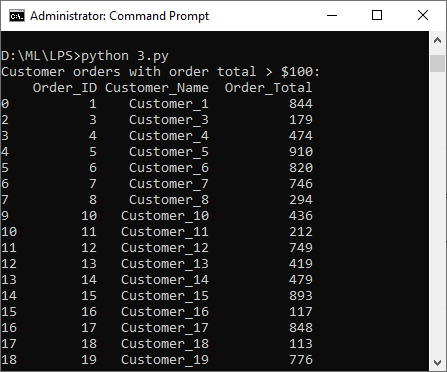
c. Filter and display rows from a dataset of customer orders where the order total is greater than $100
The following exercise uses a dataset customers.csv
import pandas as pd
# Load the data from the 'customers.csv' file into a DataFrame
orders = pd.read_csv("customers.csv")
# Filter and display rows where the order total is greater than $100
filtered_orders = orders[orders['Order_Total'] > 100]
print("Customer orders with order total > $100:")
print(filtered_orders)
Output
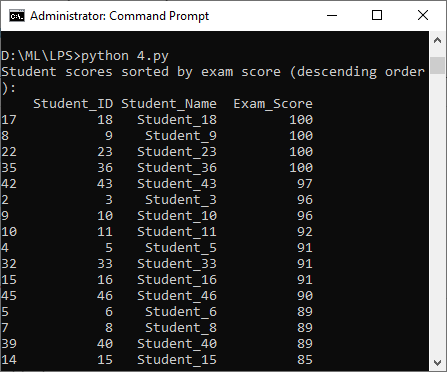
d. Sort a dataset of student scores in descending order based on their exam scores
The following exercise uses the dataset students.csv
import pandas as pd
# Load the data from the 'students.csv' file into a DataFrame
student_scores = pd.read_csv("students.csv")
# Sort the DataFrame by 'Exam_Score' in descending order
sorted_scores = student_scores.sort_values(by='Exam_Score', ascending=False)
# Display the sorted DataFrame
print("Student scores sorted by exam score (descending order):")
print(sorted_scores)
Output
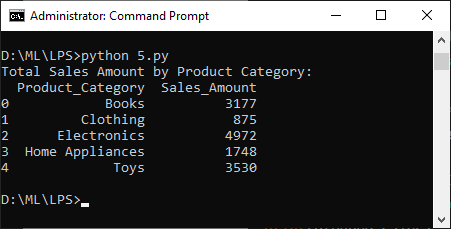
e. Group a dataset of sales transactions by product category and calculate the total sales amount for each category
The following exercise uses the dataset sales.csv
import pandas as pd
# Load the data from the 'sales.csv' file into a DataFrame
sales = pd.read_csv("sales.csv")
# Group the sales transactions by product category and calculate total sales amount
grouped_sales = sales.groupby('Product_Category')['Sales_Amount'].sum().reset_index()
# Print the grouped sales data
print("Total Sales Amount by Product Category:")
print(grouped_sales)
Output
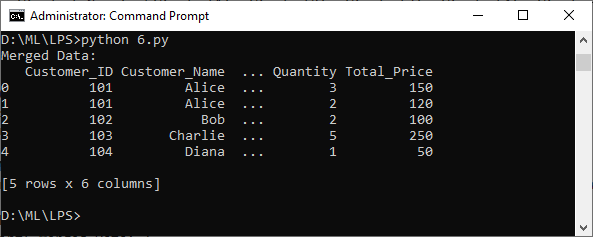
f. Merge two DataFrames containing customer information and purchase history based on a common customer ID:
import pandas as pd
# Sample data for customer_info DataFrame
customer_info_data = {
'Customer_ID': [101, 102, 103, 104],
'Customer_Name': ['Alice', 'Bob', 'Charlie', 'Diana'],
'Email': ['alice@example.com', 'bob@example.com', 'charlie@example.com', 'diana@example.com']
}
# Sample data for purchase_history DataFrame
purchase_history_data = {
'Customer_ID': [101, 102, 103, 104, 101],
'Product_Name': ['Product1', 'Product2', 'Product3', 'Product4', 'Product5'],
'Quantity': [3, 2, 5, 1, 2],
'Total_Price': [150, 100, 250, 50, 120]
}
# Create DataFrames from the sample data
customer_info = pd.DataFrame(customer_info_data)
purchase_history = pd.DataFrame(purchase_history_data)
# Merge the DataFrames based on the 'Customer_ID' column
merged_data = pd.merge(customer_info, purchase_history, on='Customer_ID', how='inner')
# Print the merged data
print("Merged Data:")
print(merged_data)
Output
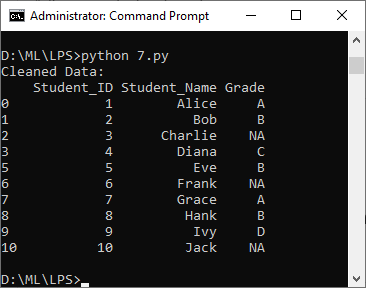
g. Clean a dataset containing student records by handling missing values in the “Grade” column and removing duplicate entries
The following exercise uses a dataset grades.csv
import pandas as pd
# Load the data from the 'grades.csv' file into a DataFrame
data = pd.read_csv("grades.csv")
# Handling missing values in the 'Grade' column by filling them with 'NA'
data['Grade'].fillna('NA', inplace=True)
# Removing duplicate entries
cleaned_data = data.drop_duplicates()
# Print the cleaned data
print("Cleaned Data:")
print(cleaned_data)
Output
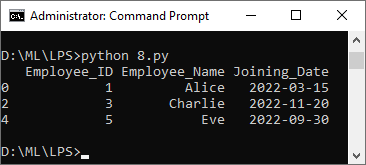
h. Create a new DataFrame containing only employees who joined the company in the last year from a dataset of employee information
The following exercise uses a dataset employees.csv
import pandas as pd
from datetime import datetime
# Load the data from the 'employees.csv' file into a DataFrame
employee_info = pd.read_csv("employees.csv")
# Calculate the current year
current_year = datetime.now().year
# Filter employees who joined in the last year
last_year_joiners = employee_info[employee_info['Joining_Date'].str.startswith(f"{current_year - 1}")]
print(last_year_joiners)
Output
i. Export a cleaned DataFrame as a new CSV file named “cleaned_data.csv” for further analysis
The following exercise makes use of a dataset called grades.csv mentioned above.
import pandas as pd
# Load the dataset from grades.csv
grades_df = pd.read_csv("grades.csv")
# Handle missing values in the 'Grades' column by filling them with 'NA'
grades_df['Grade'].fillna('NA', inplace=True)
# Remove duplicate entries based on the 'Student' column
grades_df.drop_duplicates(subset='Student_Name', keep='first', inplace=True)
# Export the cleaned data to cleaned_data.csv
grades_df.to_csv("cleaned_data.csv", index=False)
print("The cleaned data has been saved to 'cleaned_data.csv'.")
Output
Further Reading
Spring Framework Practice Problems and Their Solutions
Logistic Regression from Scratch
Wake Up to Better Performance with Hibernate
Data Science in Insurance: Better Decisions, Better Outcomes
Breaking the Mold: Innovative Ways for College Students to Improve Software Development Skills
- Angular
- ASP.NET
- C
- C#
- C++
- CSS
- Dot Net Framework
- HTML
- IoT
- Java
- JavaScript
- Kotlin
- PHP
- Power Bi
- Python
- Scratch 3.0
- TypeScript
- VB.NET